On the latest JUGUA meeting Igor Dmitriev has delivered a talk about minor, behind the scenes changes in JDK. On of them, seems to be widely-known, was HashMap being intelligent enough to turn buckets which are actually long linked lists (because of pure hashCode implementation) into search-trees. Anyway, Igor greatly explained it in a very detailed manner. One thing that was unclear for me, and Igor was not able to explain it as well, is why search tree is constructed for keys which do not have ordering? After some time investigating this question at home, seems like I have the answer.
Preface
First, the puzzler with a well-known solution. What’s wrong with this code?
Not a big secret, because of very bad hash code function, all entries will go the same bucket and form a linked list with poor performance.
Good news is that Java is clever enough to transform this list into self-balancing binary search tree after the size of the problem (and map) is big enough.
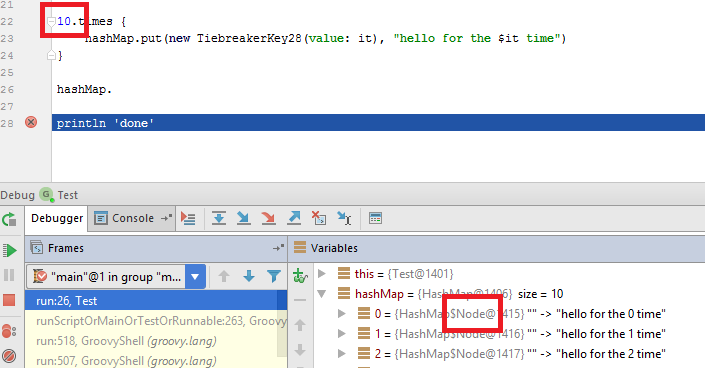
Putting into simple words, for 10 elements with same hash code we will get a linked list:
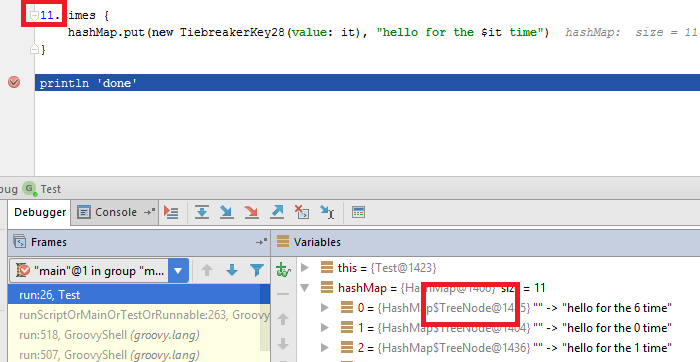
For 11 elements, list will be treeified:
Closer to the problem
The attentive reader will ask: if HashMap organizes self-balancing binary search tree, how does it determine an order of elements, which is the must for this data structure? Well, if you class luckily implements Comparable interface, it’s pretty easy job:
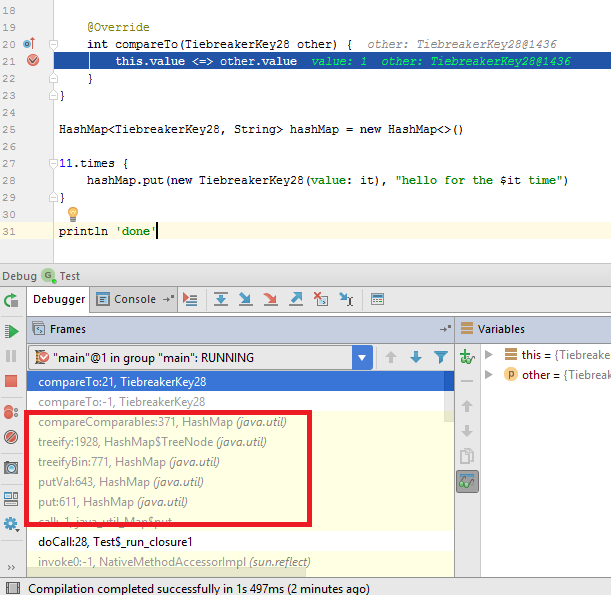
But what if not? In this case as a tiebreaker, HashMap uses System.identityHashCode(). Or simpler, some value unique and constant for each instance.
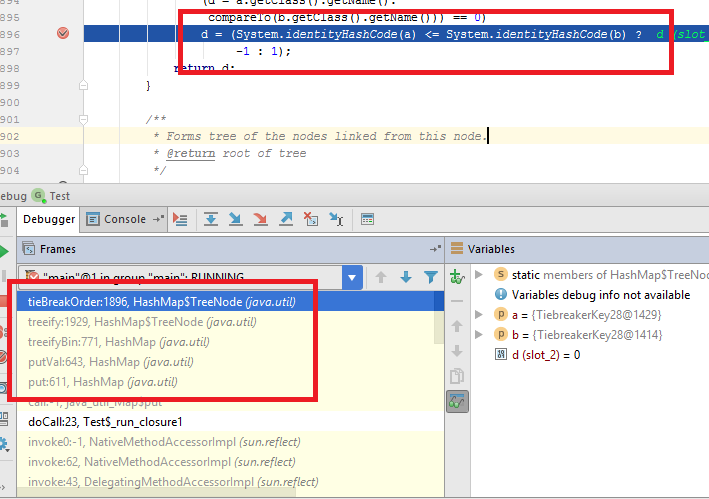
So long! What’s the problem?
The problem is that HashMap does not use tiebreak order on get operation.
If key class implements Comparable, get operation uses search tree feature:
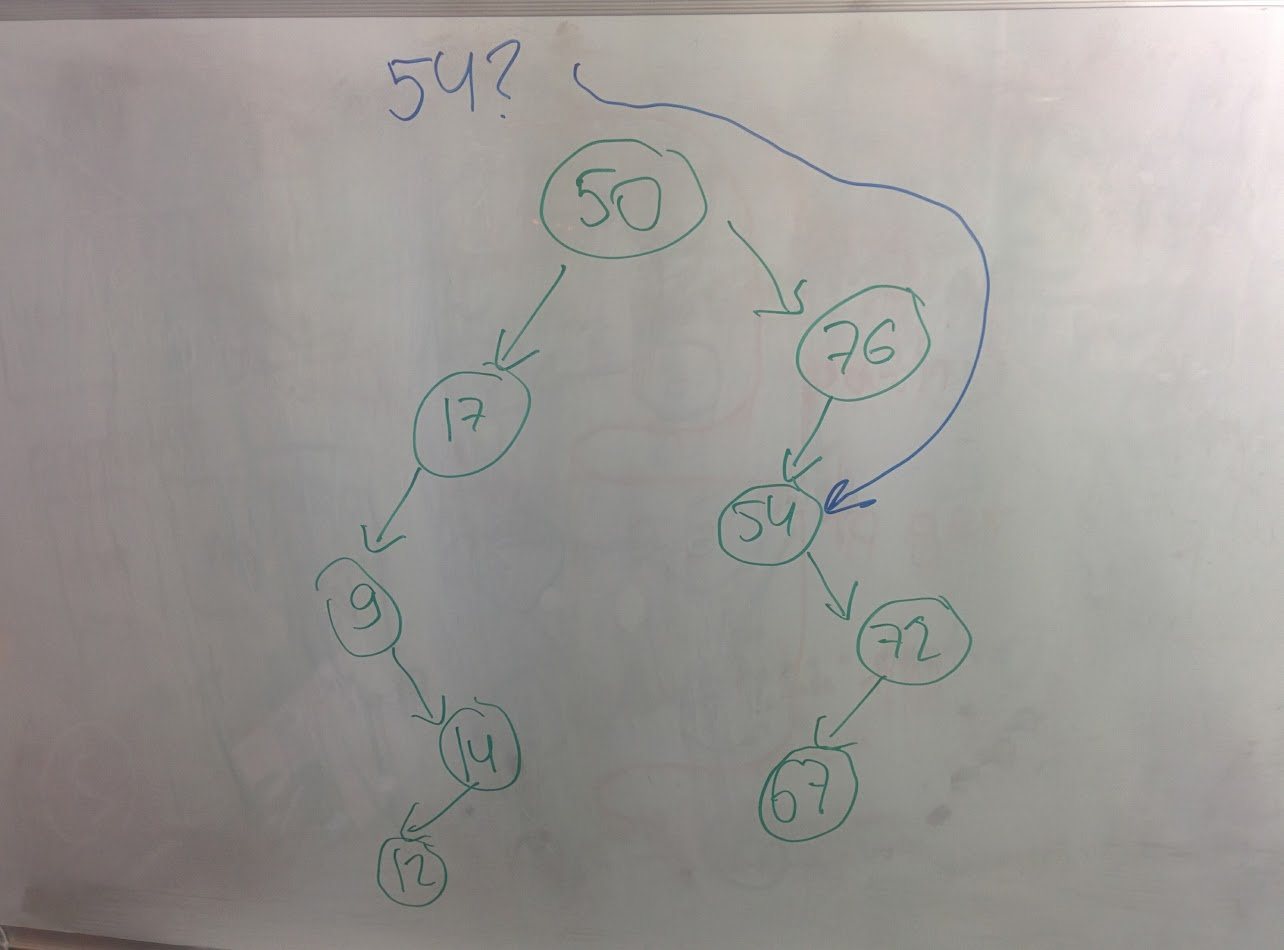
If key class does not implement Comparable, it will traverse all the tree to find specified entry:
Given this, two questions occur one by one:
Q-1. Why is tiebreak order not used?
A-1. This one is easy:
By definition, two equal object instances will have different identity hash code, so we can’t use it as a comparator.
Q-2. If we need to traverse the full tree, why HashMap bothers itself with constructing a tree? No benefits, just wasted time on tree creation!
Answer
It’s so simple! HashMap can contain keys of different classes. And some of them may be comparable and some of them not.
What does this mix imply? If we compare two keys of different classes, result is based on class name:
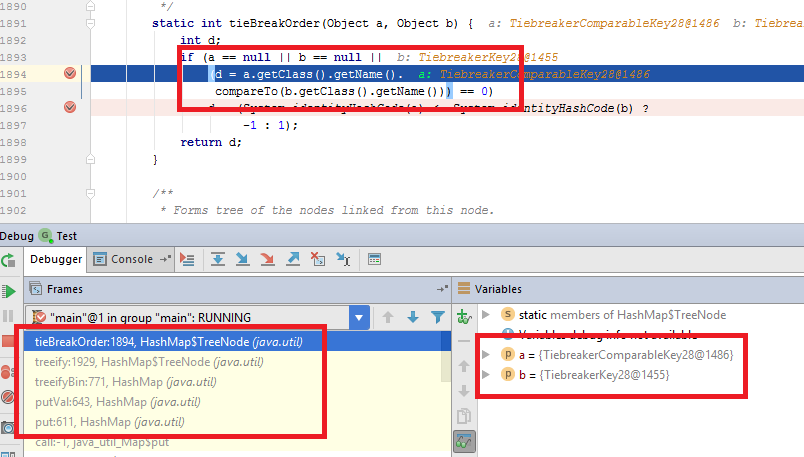
This means that key mix is pretty straightforward: first, all keys from first class goes, and then all from the second.
If we compare two keys of the same class, original rules are used: compareTo() or System.identityHashCode() is invoked.
And now, the main conclusions:
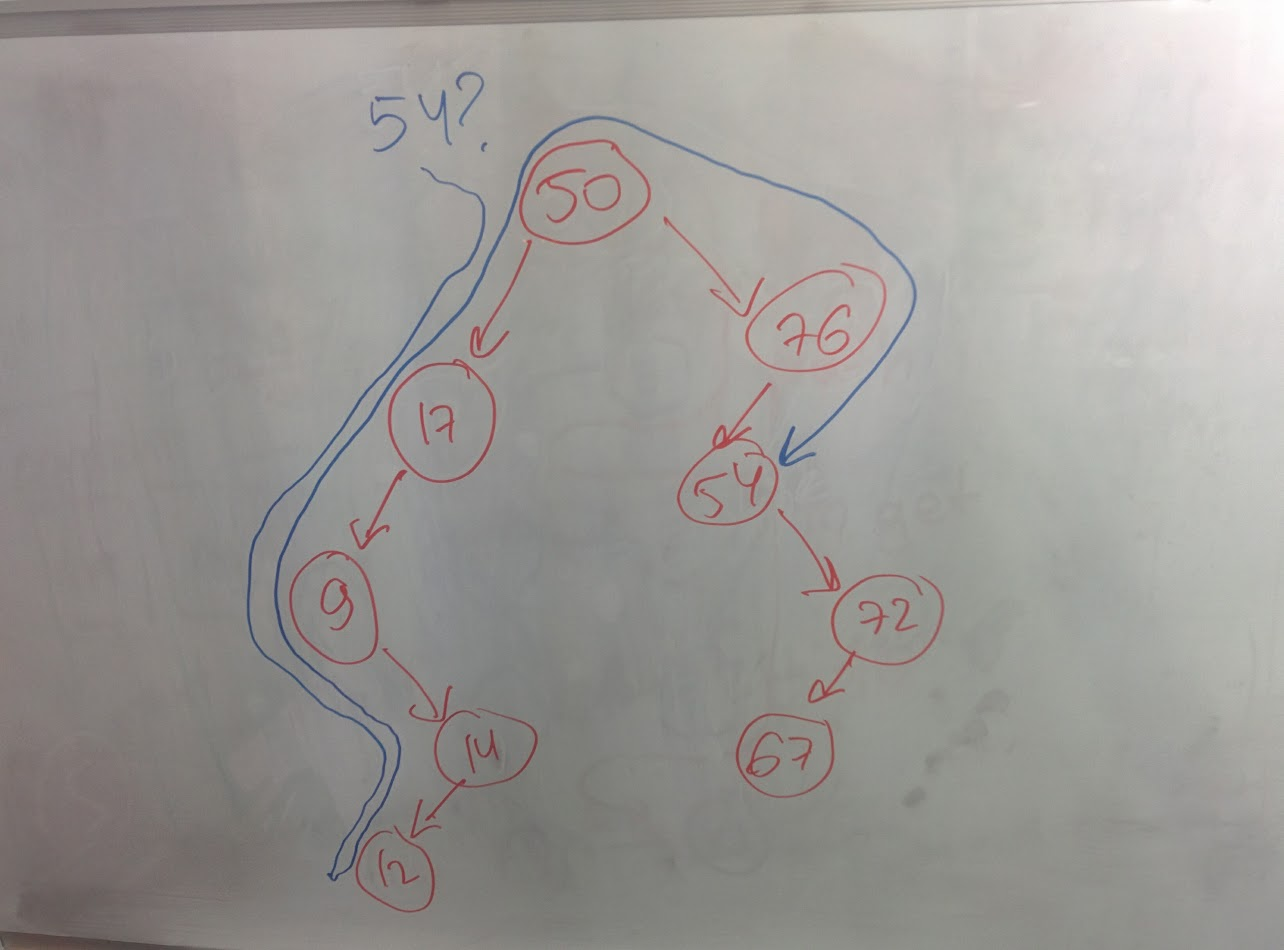
if we want to get incomparable key from the map, full traverse is used:
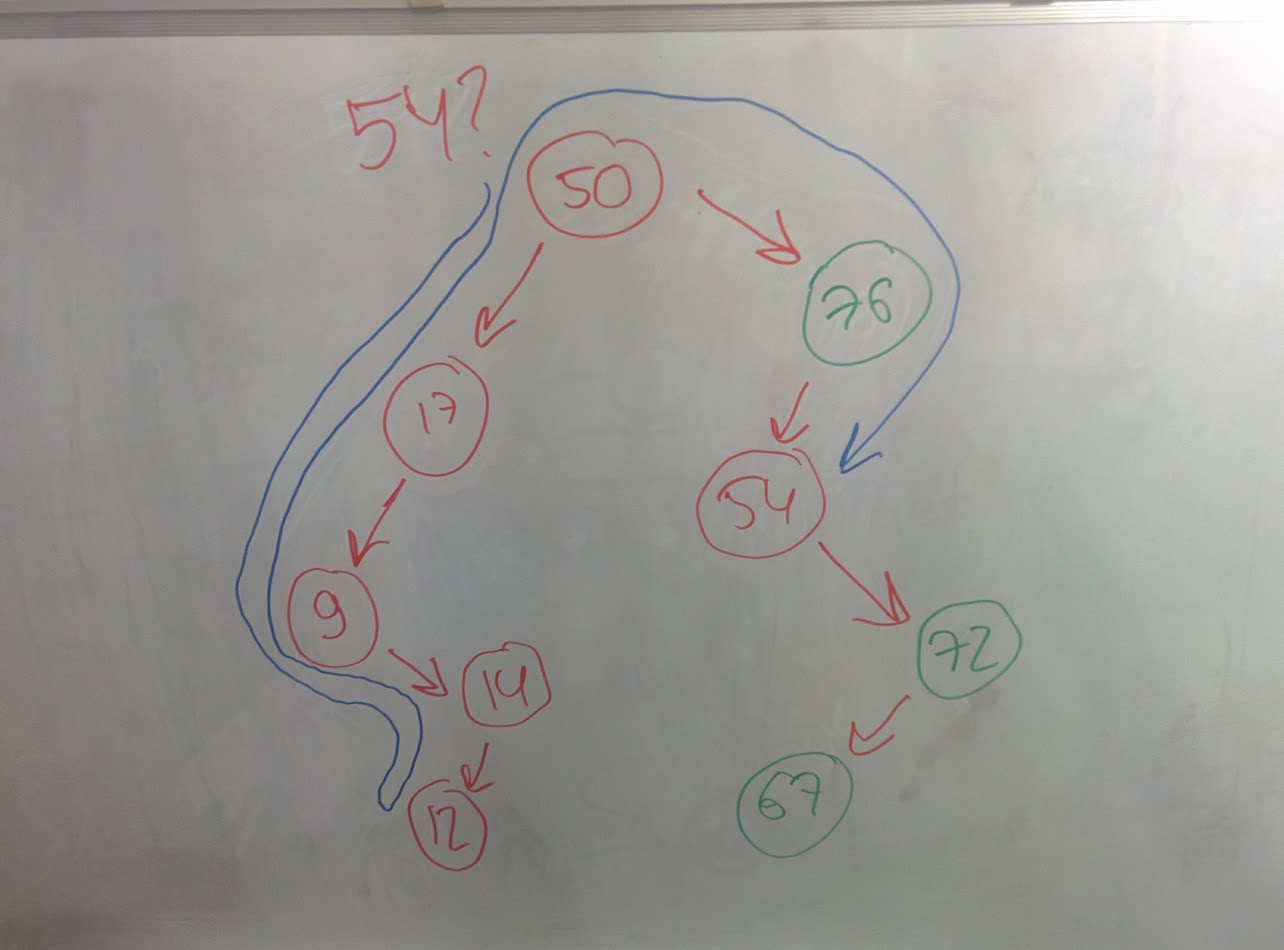
if we want to get comparable key from the map, while it goes through comparable keys on its way through the tree, it may use search-tree feature for quick search:
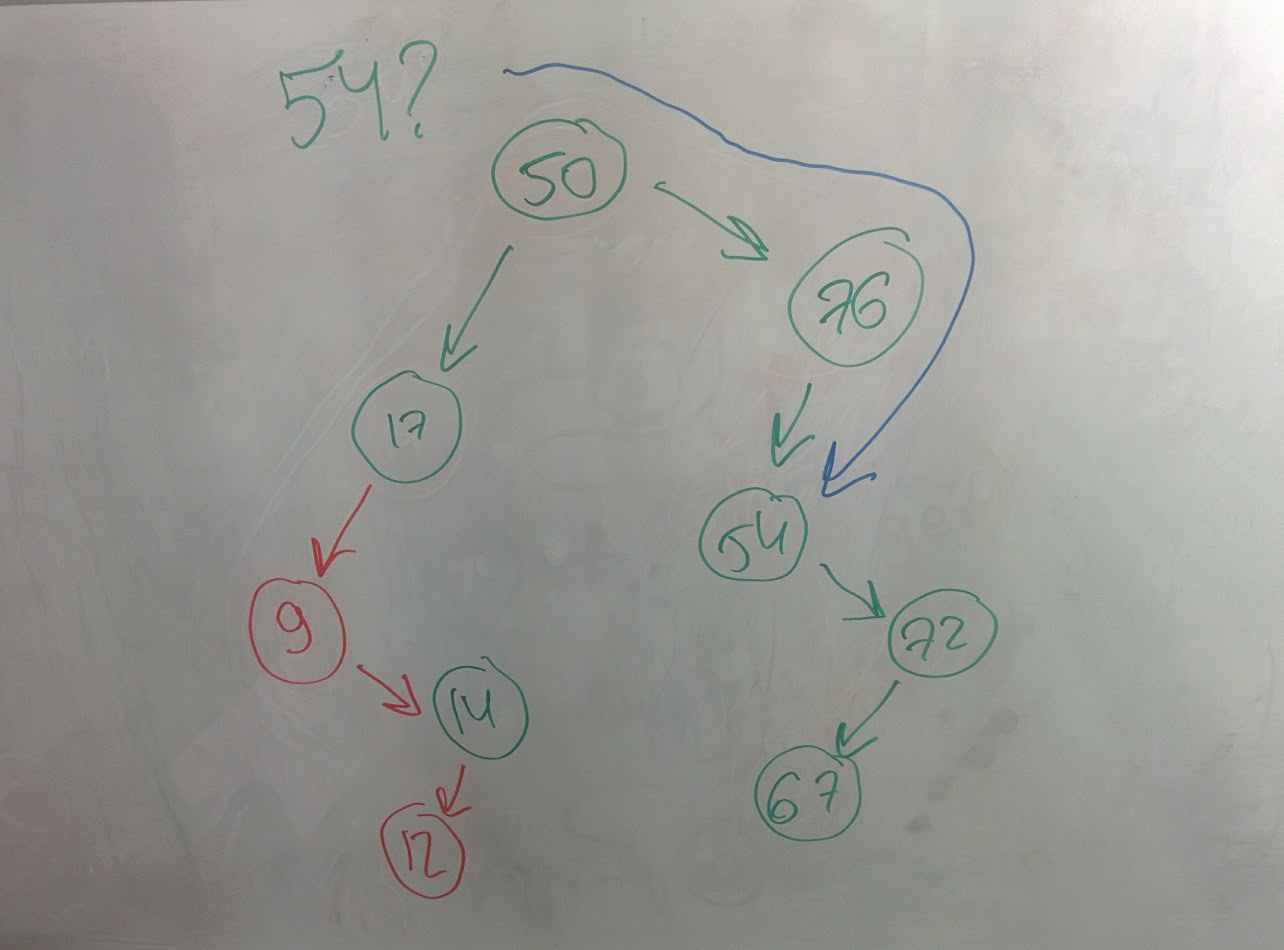
Conclusion
One of my most favorite feature of programming craft, is that there are so many magic things, which after several hours of investigation turns into very rational decisions.